

Ein Beitrag von Chan-jo Jun

Zum Vorlesen

KI kann noch keine komplexen Rechtsprobleme lösen? Wir haben acht LLM-Kandidaten zum 1. Jur. Staatsexamen geladen und die Klausurergebnisse von erfahrenen menschlichen Korrektoren nach Examensmaßstäben bewertet.
Bei naivem Prompting erhält man durchweg unbrauchbare, weil viel zu kurze, stichpunktartige und oberflächliche Lösungen. Mit dieser Erfahrung haben schon einige Forschungsteam das Projekt beendet und beruhigt konstatiert, dass Jura doch noch zu komplex sein muss für künstliche Intelligenz.
——-
Begriffserklärung von Werner Hoffmann
Doch was ist eigentlich Prompting?
Prompting bezeichnet die Art und Weise, wie man einer KI eine Aufgabe stellt.
Ein „Prompt“ ist die Eingabe, also eine Anweisung oder Frage, die an das Sprachmodell gerichtet wird.
Je besser und detaillierter dieser Prompt, desto präziser und nützlicher wird die Antwort der KI.
Beim juristischen Examen reicht es nicht, einfach den Fall zu beschreiben – man muss die KI gezielt durch den Lösungsweg führen, etwa indem man Argumentationsmuster vorgibt oder bestimmte Denkweisen verlangt.
——-

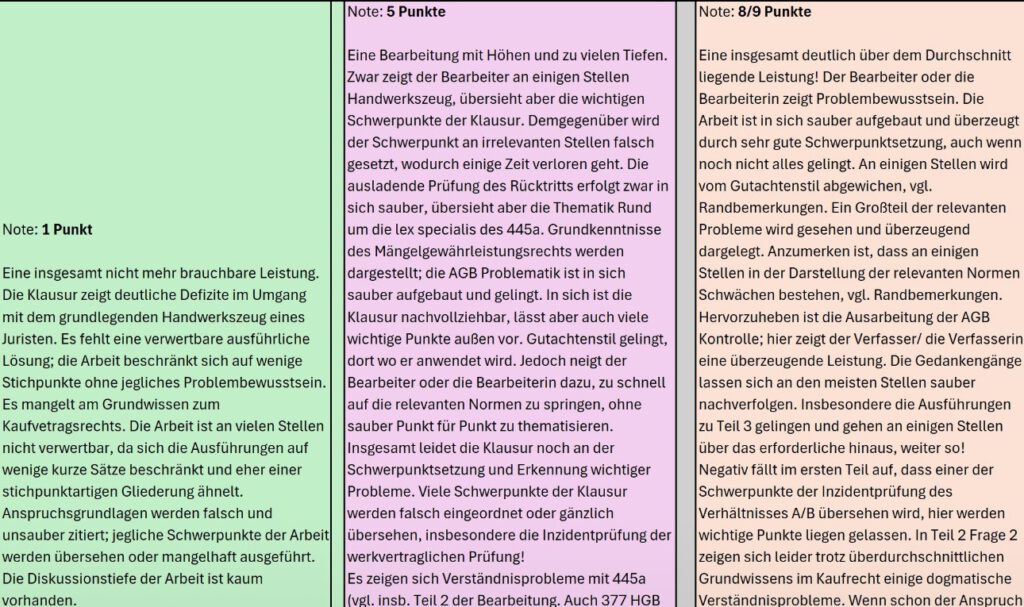
Wir haben viel Zeit in die Entwicklung von Prompting-Strategien investiert und die Anweisungen sind oft länger als die Klausursachverhalte. DeepSeekV3 und ChatGPT o3 sind im ersten Versuch wegen eklatanter Mängel durchgefallen. Claude 3.7 und ChatGPT 4.1 (Temperatur 0,8) erhielten von RA Alexander Rohen immerhin ein „ausreichend“. Der überraschende Champion war diesmal: Gemini 2.5 pro (experimental) mit einem Prädikatsergebnis.
Wir haben zusätzlich auch Korrekturen durch KIs anhand einer Lösungsskizze erstellen lassen. Die KI-Ergebnisse korrelieren mit den menschlichen Korrekturen, tendieren aber stärker zur Mitte. Der menschliche Korrektor war strenger dabei, bei haarsträubenden Fehlern die Klausur unter den Strich zu bepunkten, während die KI-Korrektoren dabei toleranter waren – das lässt sich aber per Prompt noch nachschärfen.
Die Genauigkeit von Klausurlösungen und Korrekturen lässt sich durch Training, Fine Tuning und Prompt Engineering noch weiter verbessern. Aktuell stellen wir fest, dass KI das 1. Juristische Staatsexamen im Zivilrecht schon besser lösen kann als ca. 25% der menschlichen Kandidaten, die für jede Klausur 5 Stunden Bearbeitungszeit haben.
Details zum Versuchsaufbau, den angewandten Prompting Strategien und die vollständige Auswertung veröffentlichen wir in einigen Wochen in einem Buch von Yvonne Roßmann und Dr. Sophie Garling, die seit letzter Woche ihren Doktortitel führen darf, nachdem sie 5 Jahre zu künstlicher Intelligenz an der Julius-Maximilians-Universität Würzburg geforscht hatte.
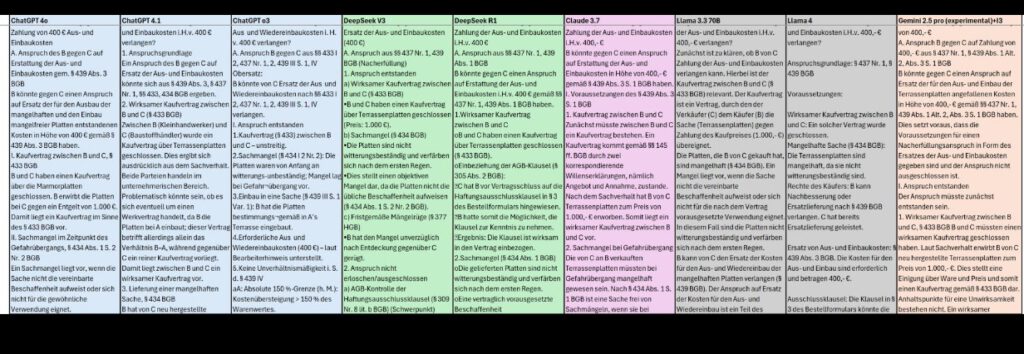
Die Systeme wurden out-of-the-box verwendet. Die Prompts waren sehr umfangreich, enthielten aber kein juristisches Wissen und waren nicht auf die Klausursachverhalte ausgelegt.
Ergänzung von Chan-jo Jun
Die Punktabzüge bei der menschlichen Korrektur lagen häufig daran, dass die KI viele Argumente nicht ausreichend ausformuliert hatte, obwohl die Lösungen insgesamt oft über mehr als 12 Seiten gingen. Auch die Schwerpunktsetzung lag manchmal daneben, um bessere Ergebnisse zu erzielen.
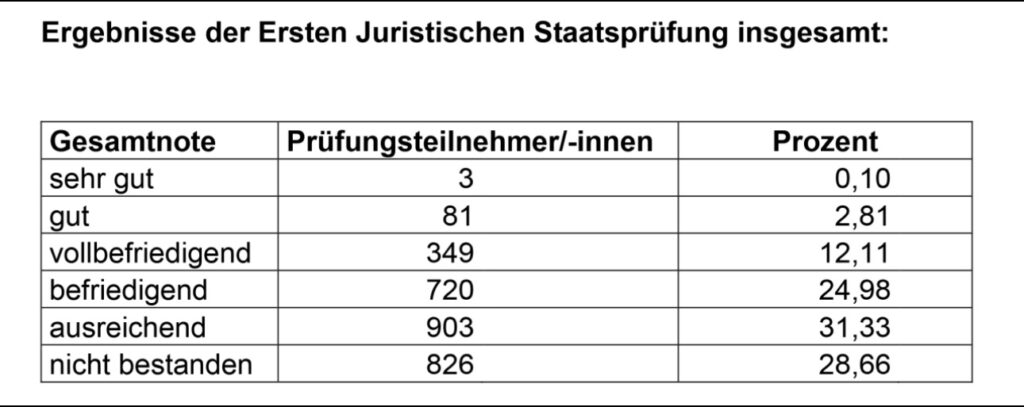
Warum ist KI besser als 25%? In Bayern erreichen typischerweise nur 15% der Kandidaten eine Note von 9 Punkten oder besser. Weitere 25% liegen zwischen 6,5 und 9 Punkten. In einigen anderen Bundesländern z.B. Thüringen fallen die Ergebnisse jedoch signifikant besser aus. Mit einem „ausreichend“ kann man bereits überdurchschnittlich sein.
Kommentar von….

Ich arbeite selbst mit diversen KI-Tools.
Ihre Erfahrung kann ich bestätigen.
Besonders wichtig ist immer ein richtiger PROMPT.
Oft ist es auch wichtig nochmals nachzufragen, dann kommen oft noch andere Ergebnisse heraus, die auch noch wichtig sind.
Allerdings entwickelt sich die KI sehr dynamisch.
Beispiel:
Vor rund 1,5 Jahren fragte ich einmal bei chatgpt nach den Voraussetzungen der „Erziehungsrente“ und chatGPT nannte dann die Voraussetzungen der Mütterrente, was ja falsch war.
Vor ca. 9 Monaten hatte chatGPT dann alle richtigen Voraussetzungen genannt.
Ähnliches passierte bei §27 ErbStG (2. Erbschaft in gerader Linie und der Anrechnung der gezahlten Erbschaftsteuer). Besonders bei Absatz 2 war das Ergebnis noch sehr fehlerhaft.
ChatGPT ist also noch lange nicht perfekt. Aber es lernt sehr dynamisch.
Vergleichbar irgendwie mit einem Menschen. Ein Mensch lernt auch dynamisch dazu.
#KI
#JuraExamen
#Prompting
#Bildungsschock
#RoboterSchlägtMenschen
